Overview of the RO Model
This section provides an overview of the RO Model. It does not cover all the details of the model. The RO Model Specification [[RO-MODEL]] provides precise definitions to be used.
Generally speaking the Wf4Ever RO model can describe the following three aspects of information:
- Basic aggregation structure of an RO.
- Workflow-centric Research Objects.
- Annotations to an RO and its components.
Describe Basic Aggregation Structure of an RO
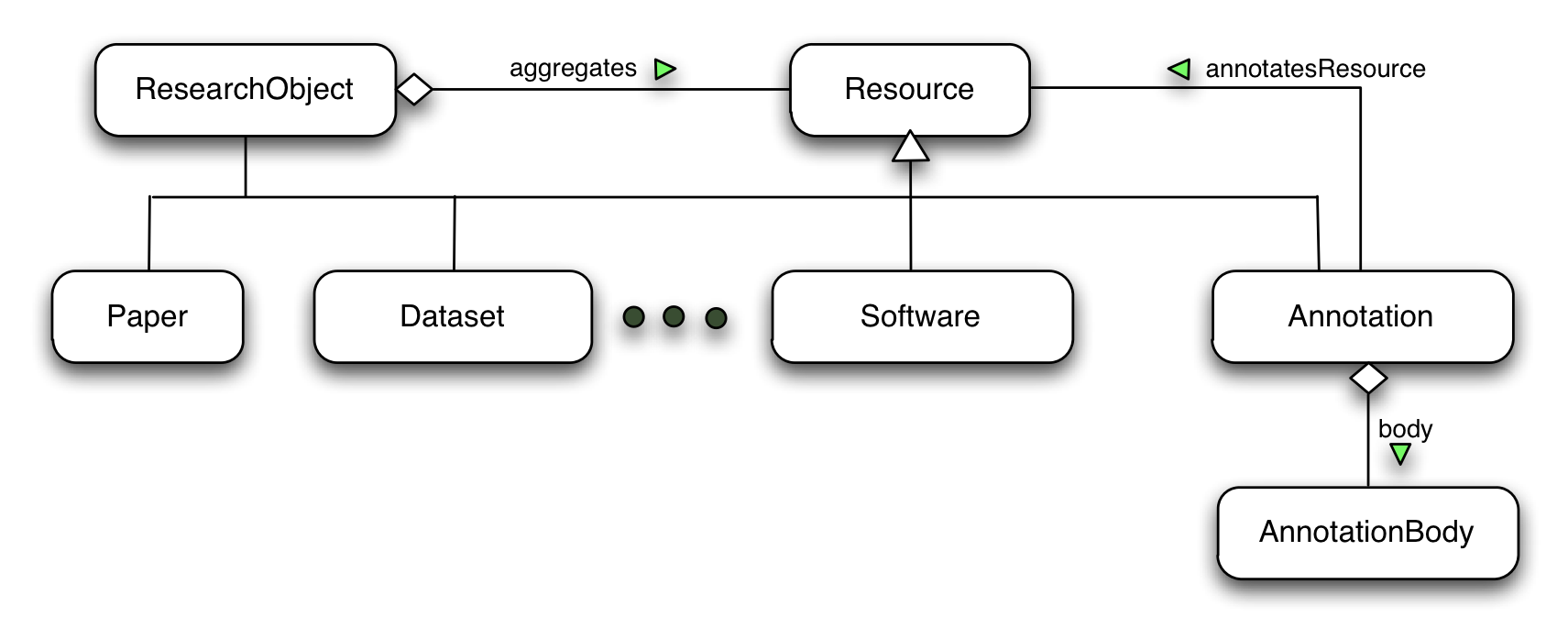
A Research Object is simply an aggregation of resources and annotations about them. The figure below provides an overview of the Wf4Ever RO Model, which includes the following constructs:
- ResearchObject, represents an aggregation of resources. It acts as an entry point to the research object.
- Resource, represents a resource that can be aggregated within a research object. As shown in the figure below, a Resource can be a Dataset, Paper, Software or Annotation. Typically, a ResearchObject aggregates multiple Resources.
- Annotation, used for describing research objects, their aggregated resources, as well as the relationship between resources.
The description of a RO, such as its structure and annotations, is provided in a manifest file. This manifest file can be aggregated as part of this RO. Examples of descring a basic RO in a manifest file can be found in Section 3.1.
Describe Workflow Centric Research Objects
A special class of research object that is the primary interest of our specification are workflow-centric research objects, which refer to research objects that aggregate workflows, or more specifically workflow templates.
- A workflow template is a network in which the nodes are processes and the edges represent data links that connect the output of a given process to the input of another process, specifying that the artifacts produced by the former are used to feed the latter.
- A process is used to describe a class of actions that when enacted give rise to process runs. Processes specify the software component (e.g., web service) responsible for undertaking those actions.
A workflow is often executed following a template which describes each step involved in the whole execution. Templates can be designed by scientists (users) with the purpose of being able to execute the same workflow many times with different inputs for their tests, as "live-tutorials" of how some data infrastructure can be more efficiently used, etc. There are two types of templates:
- Abstract workflow templates, which have some of the steps of the workflow not bound to a specific tool.
- Concrete workflow templates, which have all the steps specified.
In the RO model, we are able to describe these templates plus their relationships with the executions by using the wfdesc vocabulary.
As well as workflow templates, workflow-centric research objects contain information about workflow runs, which are obtained by enacting workflow templates, and provenance of the results obtained from the runs. Examples of describing a workflow research object can be found in Section 3.2 and 3.5.
Describe Annotations to an RO and its Components
In the RO model the Annotation Ontology is used as a generic vocabulary to allow annotations to research objects, their resources, and their relationships. Three kinds of elements are used to specify annotations:
- Annotation, represents the annotation itself.
- Target, used to specify the resource or research object subject to annotation.
- Body, the body comprises a description of the target in the form of a set of RDF statements, which can be specifying the date of creation of the target, or its relationship with other resources or research objects.
Annotations may be provided primarily for human consumption (e.g. a description of a hypothesis that is tested by a workflow-based experiment), or for machine consumption (e.g. a structured description of the provenance of results generated by a workflow run). Both kinds of annotations are accommodated using Annotation Onology structures. Examples of expressing annotations to an RO and its components can be found in Section 3.3 and 3.4.